
파워쿼리로 수동 크롤링을 끝내는 실시간 ETL 파이프라인 구축
Web Data Import 아키텍처의 부재가 실무 현장에서 얼마나 끔찍한 비효율과 데이터 오염을 낳는지, 나는 타 부서에서 취합된 엑셀 보고서를 열어볼 때마다 매일같이 목격한다. 환율, 기준 금리, 글로벌 기업의 주가 등 실시간으로 변동하는 외부 지표를 내부 재무 모델이나 실적 보고서에 결합해야 할 때, 대다수의 실무자들은 여전히 포털 사이트의 금융 페이지를 띄우고 표 영역을 통째로 마우스로 드래그해 복사(Ctrl+C)한 뒤 자신의 시트에 강제로 붙여넣기(Ctrl+V)를 시전한다. 이 단순 무식한 수동 크롤링 행위는 당장의 빈칸은 채울 수 있을지 몰라도, 시스템 데이터 아키텍처 관점에서는 언제 터질지 모르는 시한폭탄을 심는 것과 다름없다. 웹 페이지의 HTML 테이블을 엑셀로 강제 이식하는 과정에서 화면에는 보이지 않는 웹 서식, 더미 하이퍼링크, 그리고 인쇄할 수 없는 공백(CHAR 160) 문자열이 원본 데이터에 거머리처럼 달라붙어 들어오기 때문이다.
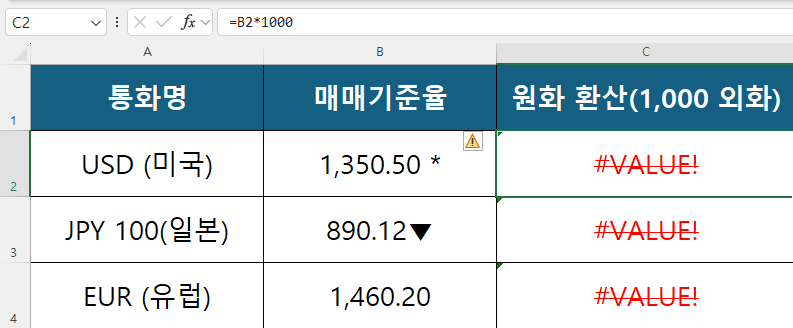
이렇게 프론트엔드 단계에서부터 오염된 채 유입된 비정형 텍스트 뭉치는 후행하는 모든 데이터 모델링을 마비시킨다. 숫자여야 할 환율 데이터가 보이지 않는 텍스트 포맷으로 강제 변환되어 있어 SUM이나 AVERAGE 연산에서 #DIV/0! 또는 #VALUE! 에러를 뿜어내고, 미세한 특수문자 탓에 VLOOKUP 함수의 참조 값을 영구적으로 이탈시켜 버린다. 더욱 심각한 리스크는 데이터의 ‘업데이트 주기’에 있다. 매일 오전 9시마다 최신 지표로 환차손익 모델을 갱신해야 한다면, 담당자는 매일 아침 브라우저를 열고 동일한 복사 붙여넣기 노가다를 반복해야 한다. 인간의 성실함과 기억력에 의존하는 수동 파이프라인은 필연적으로 누락과 오입력이라는 휴먼 에러를 동반하며 데이터의 신뢰성을 근본적으로 파괴한다. 수작업으로 망가진 데이터를 사후에 정제하는 데 시간을 쏟는 것은 실무자의 직무 유기다. 데이터는 흐르는 물처럼 소스에서 목적지까지 시스템을 타고 자동으로 흘러야 하며, 이 데이터 수집 파이프라인에 인간의 마우스 클릭이나 타이핑이 개입할 여지를 원천적으로 차단해야만 한다.
Web Data Import 엔진의 백엔드 로직과 아키텍처
이러한 수동 크롤링의 비효율을 시스템적으로 도려내고 데이터 추출부터 정제까지의 전 과정을 자동화하기 위해 내가 실무에 도입하는 핵심 아키텍처가 바로 파워쿼리(Power Query)를 활용한 Web Data Import 파이프라인 구축이다. 이 기능은 단순한 매크로 기록이나 복사 붙여넣기의 연장선이 아니다. 엑셀 내부에 네이티브로 탑재된 강력한 ETL(Extract, Transform, Load) 엔진이 사용자가 지정한 타겟 URL로 직접 HTTP GET 요청을 보내 백그라운드에서 웹 페이지의 소스 코드를 읽어 들이고, 그 안의 정형화된 데이터만을 정밀하게 추출해 내는 고도화된 과정이다. 복잡한 파이썬(Python) 크롤링 코드를 짜거나 별도의 외부 스크래핑 라이브러리를 설치할 필요 없이, URL 하나만 던져주면 엑셀 스스로가 웹 스크래퍼(Web Scraper)로 동작하여 완벽한 추출 작업을 수행한다. 시스템을 세팅하기 위해 상단 리본 메뉴의 [데이터] 탭에서 [웹]을 클릭하고, 타겟이 되는 금융 포털의 환율 고시 URL을 입력한다. 연결이 승인되면 파워쿼리 편집기 창이 열리며, 엑셀은 이 추출 과정을 M 함수(M-Code)라는 자체적인 백엔드 언어로 다음과 같이 기록한다.
Source = Web.Page(Web.Contents(“타겟_웹_페이지_URL”)),
Data = Source{0}[Data],
ChangedType = Table.TransformColumnTypes(Data,{{“통화명”, type text}, {“매매기준율”, type number}})
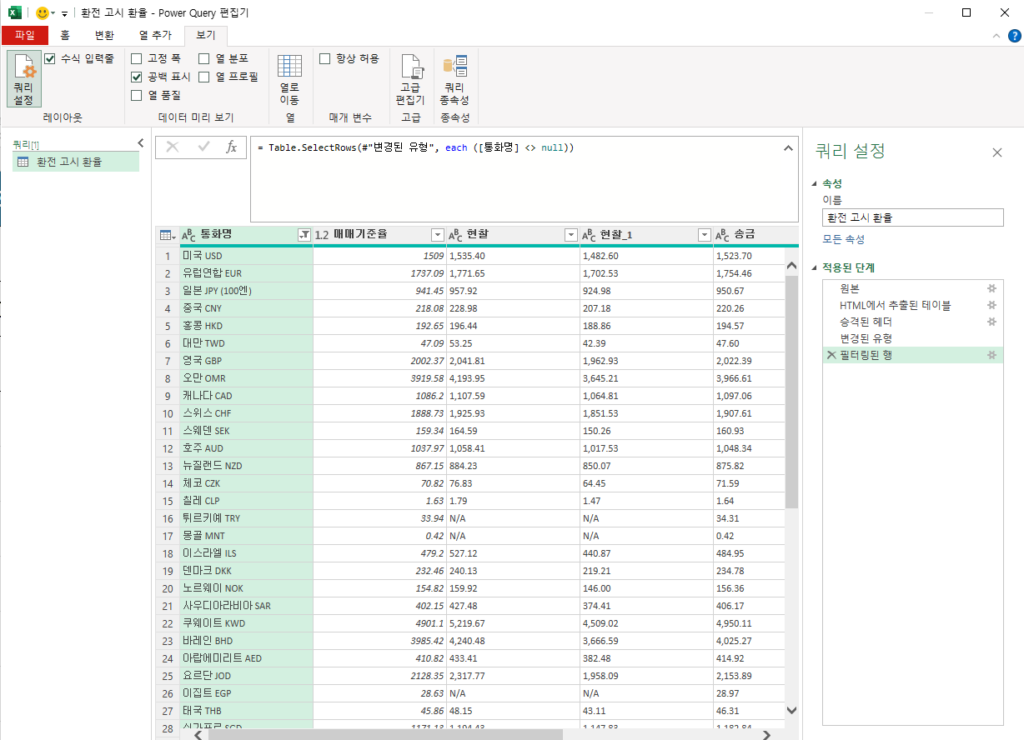
이 M 함수 로직의 작동 원리는 데이터베이스 구조론에 입각해 명확히 해석될 수 있다. 첫 번째 줄의 Web.Contents 함수는 우리가 엔진에 던져준 URL의 서버에 다이렉트로 접속하여 페이지의 순수한 HTML 바이너리(Binary) 데이터를 통째로 긁어온다. 이것이 Web Data Import의 물리적인 시작점이다. 그다음 이를 감싸고 있는 Web.Page 함수가 파서(Parser) 역할을 수행하여, 복잡한 바이너리 소스 코드 덩어리 속에서 <table> 태그로 구성된 정형 데이터 블록만을 논리적으로 해체해 낸다. 화면에 여러 개의 광고나 무의미한 표가 존재하더라도, 인덱스 번호(예: Source{0}) 매핑을 통해 우리가 타겟팅하는 정확한 환율 표 객체만을 핀셋으로 집어 올린다.
가장 핵심적인 데이터 무결성 방어 로직은 마지막 줄의 Table.TransformColumnTypes 단계다. 웹에서 긁어온 날것의 데이터는 기본적으로 모든 형태가 텍스트(Any)로 취급되지만, 이 단계를 통해 ‘통화명’ 열은 무조건 문자(Text)로, ‘매매기준율’ 열은 무조건 십진수 숫자(Number)로 데이터 타입을 엄격하게 강제 캐스팅(Casting)한다. 이 로직이 파이프라인에 걸려있는 한, 외부 서버에서 쉼표나 기호가 섞여 들어오더라도 쿼리 엔진이 이를 정갈한 숫자로 완벽하게 정제하여 엑셀 시트에 내려보낸다. 사용자의 자율성이 배제된, 단방향의 견고한 자동화 구조가 완성된 것이다. 이 세팅이 끝난 후, 실무자는 브라우저를 켤 필요가 없다. 상단 메뉴의 ‘모두 새로 고침’ 버튼 하나만 누르면 엔진이 지정된 URL에 접속하여 최신 수치를 물고 오며, 앞서 다루었던 데이터 유효성 검사로 내부 입력을 통제하는 아키텍처와 맞물려 내외부 데이터의 무결성을 동시에 달성하게 된다.
실무 적용 시 Web Data Import 시스템의 기술적 한계
그러나 이처럼 무결해 보이는 Web Data Import 시스템도 실무 환경에 배포할 때는 철저히 외부 환경에 종속된다는 치명적인 기술적 한계점을 인지하고 통제해야 한다. 이 아키텍처의 가장 큰 약점은 추출 대상이 되는 웹 페이지의 HTML DOM(Document Object Model) 구조 무결성에 전적으로 의존한다는 것이다. 만약 타겟 URL의 웹사이트 관리자가 페이지 디자인을 전면 개편하여 기존 표의 태그 속성을 변경해 버리거나, 정적 테이블이 아닌 비동기식 렌더링(JavaScript CSR) 방식으로 데이터를 호출하도록 아키텍처를 수정한다면, 우리의 Web.Page 함수는 목표물을 찾지 못하고 즉각 Expression.Error(표를 찾을 수 없음)를 뿜어내며 파이프라인을 멈춰 세운다. 파워쿼리는 정적인 HTML 페이지를 파싱하는 데는 압도적인 퍼포먼스를 내지만, 동적으로 생성되는 자바스크립트 객체를 렌더링하는 브라우저 에뮬레이터 기능은 내장되어 있지 않기 때문이다. 파워쿼리 웹 커넥터의 구조적 제약과 호환성에 대한 보다 심도 있는 기술 문서는 마이크로소프트 공식 파워쿼리 Web 지원 문서에서 확인할 수 있다.
또한, 사내 보안망의 방화벽 정책에 따라 엑셀 프로그램이 외부망 포트로 HTTP 요청을 보내는 행위 자체가 인바운드/아웃바운드 규칙에 의해 차단될 수도 있으며, 지나치게 빈번한 새로 고침 트래픽을 유발할 경우 대상 웹 서버의 안티 스크래핑(Anti-Scraping) 로직에 의해 사무실 IP가 일시적으로 블록당하는 변수도 존재한다. 따라서 이 파이프라인을 운용할 때는 데이터 소스의 엔드포인트(Endpoint)가 장기적으로 안정성을 유지할 수 있는 공공 데이터 포털이나 대형 금융사의 정적 페이지를 우선적으로 타겟팅하는 보수적인 접근이 필요하다. 타 부서에서 던져주는 오염된 텍스트 뭉치와 수동 복사 붙여넣기의 늪에서 벗어나, 엑셀 엔진이 백그라운드에서 직접 데이터를 수급해 오는 자동화 구조를 빌드했다. 외부 웹 서버의 구조적 변동이라는 불가항력적 예외 사항만 주기적으로 모니터링한다면, 데이터의 추출부터 정제까지 이어지는 무결성 검증은 이제 온전히 시스템의 몫이다. 나는 파이프라인을 타고 흘러들어온 정갈한 숫자들을 바탕으로, 엑셀의 본질인 데이터 분석이라는 통찰에만 집중할 뿐이다.