
텍스트 나누기 마법사 켜는 노가다, 이제 그만합시다
안녕하세요. 여러분의 퇴근 시간을 책임지는 엑셀 자동화 마스터, 직장인 엑셀 꿀팁 저장소입니다! 오늘은 엑셀 실무자라면 누구나 한 번쯤 겪어봤을 ‘데이터 전처리(Pre-processing)’의 지옥에서 여러분을 구출해 드릴 강력한 무기, TEXTBEFORE / TEXTAFTER 함수의 모든 것을 파헤쳐 보겠습니다.
지난 시간에는 복잡한 중첩 수식을 깔끔하게 정리해 주는 LET 함수의 기적에 대해 알아봤습니다. 수식은 스마트해졌는데, 만약 그 수식이 참조해야 할 원본 데이터(Raw Data) 자체가 쓰레기(?) 상태라면 어떨까요?
마케팅팀 최 사원의 오늘 아침 상황을 들여다봅시다. 타 부서에서 “이번 시즌 신상품 리스트입니다”라며 5,000행짜리 엑셀 파일을 넘겨줬습니다. 기분 좋게 파일을 열어본 최 사원은 그만 얼어붙고 말았습니다. 제품명, 브랜드, 사이즈, 색상 등 모든 정보가 [2024_SS_신상_나이키_운동화_Black_270] 처럼 언더바(_) 하나에 의지해 한 셀에 떡하니 뭉쳐져 있었기 때문입니다. 팀장님은 당장 점심시간 전까지 “브랜드별 재고 현황이랑 사이즈 분포표 뽑아와”라고 지시하고 회의실로 들어갔습니다.
최 사원은 급한 마음에 [데이터] 탭의 ‘텍스트 나누기’ 기능을 켭니다. 하지만 어떤 셀은 언더바가 3개고, 어떤 셀은 4개라 열이 밀리기 시작합니다.
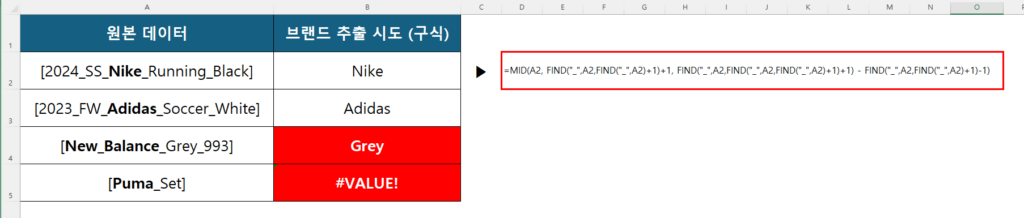
결국 =LEFT(A1, FIND("_", A1)-1) 같은 구식 함수를 끄적여보지만, 괄호 개수 맞추다가 #VALUE! 에러만 잔뜩 띄우고 멘탈이 나가버립니다. 이런 원시적인 노가다는 이제 끝내야 합니다. 오늘 소개할 함수를 장착하면, 원하는 글자 앞뒤를 레이저 커팅기로 자르듯 칼같이 발라낼 수 있습니다.
LEFT, MID, FIND 함수가 ‘최악’인 이유
지금까지 우리는 텍스트를 추출할 때 LEFT, MID, RIGHT 함수와 FIND 함수를 억지로 조합해서 썼습니다. 이 방식이 왜 문제일까요?
- 가독성 제로:
=MID(A1, FIND("-", A1)+1, FIND("-", A1, FIND("-", A1)+1)-FIND("-", A1)-1)… 이게 도대체 무슨 뜻인지 한눈에 들어오시나요? 나중에 수정하려고 보면 짠 사람도 기억이 안 납니다. - 유연성 부족: 글자 수가 조금만 달라지거나 구분 기호 위치가 바뀌면 수식이 즉시 에러를 뱉습니다.
- 속도 저하:
FIND함수가 수식 안에서 여러 번 반복되면 엑셀 파일이 무거워집니다.
마이크로소프트도 이 문제를 알고 있었습니다. 그래서 TEXTBEFORE(이거 앞)와 TEXTAFTER(이거 뒤)라는 직관적인 해결책을 내놓은 것입니다.
핵심 1: TEXTBEFORE 함수 – “이 기호 앞의 것만 가져와!”
이름 그대로입니다. TEXTBEFORE는 내가 지정한 특정 기호(구분자)의 앞(Before)에 있는 텍스트를 몽땅 가져오는 함수입니다. 문법도 아주 간단합니다.
=TEXTBEFORE(text, delimiter, [instance_num], [match_mode], [match_end], [if_not_found])
복잡해 보이죠? 실무에서는 딱 두 가지만 기억하면 됩니다. “어떤 셀에서(text)”, “무슨 기호 앞까지(delimiter)” 자를 것인가.
기초 활용: 이메일 아이디 추출하기
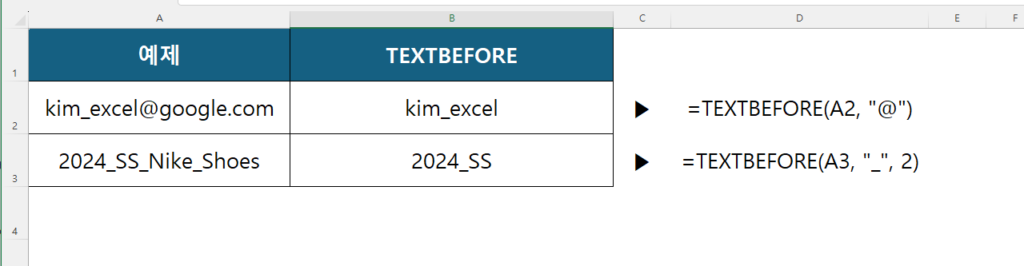
A2 셀에 kim_excel@google.com이라는 데이터가 있다고 칩시다. 여기서 @ 앞의 아이디만 필요하다면?
=TEXTBEFORE(A2, "@")
결과는 “kim_excel”입니다. FIND 함수로 위치 찾고 LEFT로 자르고… 그런 짓은 이제 안 해도 됩니다.
심화 활용: 두 번째 언더바(_) 앞까지 가져오기
만약 2024_SS_Nike_Shoes 데이터에서 2024_SS까지 가져오고 싶다면 어떻게 할까요? 언더바가 여러 개라 헷갈립니다. 이때 세 번째 인수 [instance_num]을 사용합니다.
=TEXTBEFORE(A3, "_", 2)
이 수식은 “두 번째 언더바(_)를 찾아서 그 앞을 다 가져와!”라는 뜻입니다. 결과는 “2024_SS”가 됩니다. 정말 쉽죠?
핵심 2: TEXTAFTER 함수 – “이 기호 뒤의 것만 가져와!”
반대로 특정 기호 뒤(After)에 있는 내용을 가져오고 싶다면 TEXTAFTER를 쓰면 됩니다. 이 함수에는 실무자들이 환호할 만한 엄청난 비밀 기능이 하나 숨어 있습니다. 바로 ‘음수 마이너스(-)’ 인덱싱입니다.
기초 활용: 도메인 추출하기
위의 이메일 예제에서 @ 뒤의 주소만 필요하다면?
=TEXTAFTER(A2, "@") ➔ 결과: “google.com”
고급 꿀팁: 파일 확장자만 쏙 뽑아내기 (음수 활용)
이 기능이 진짜 대박입니다. 윈도우 파일 경로를 다루다 보면 C:\Users\Documents\Report_Final_v2.xlsx 처럼 경로가 제각각인 경우가 많습니다. 여기서 맨 뒤의 파일명(Report_Final_v2.xlsx)만 가져오고 싶다면?
슬래시(\)가 몇 개인지 세야 할까요? 아닙니다. instance_num에 -1을 넣으면 ‘뒤에서부터’ 셉니다.
=TEXTAFTER(A3, "\", -1)
이 수식은 “오른쪽 끝에서부터 첫 번째 슬래시(\)를 찾고, 그 뒤를 가져와!”라는 뜻입니다. 경로가 아무리 길어도 파일명만 정확하게 추출합니다. 이 기능 하나만 알아도 야근 1시간은 줄일 수 있습니다.
최종 병기: 앞뒤로 다 발라내는 ‘샌드위치 기법’
자, 다시 최 사원의 [ 문제로 돌아가 봅시다. 여기서 중간에 끼어있는 브랜드 ‘2024_SS_Nike_Shoes]Nike
논리는 간단합니다. “두 번째 언더바 뒤에 있는 걸 가져오고, 그 결과에서 다시 첫 번째 언더바 앞을 자른다.”
- 먼저
TEXTAFTER로 앞부분을 날립니다:=TEXTAFTER(A4, "_", 2)➔ 결과:Nike_Shoes - 그 결과에
TEXTBEFORE를 씌워서 뒷부분을 날립니다:=TEXTBEFORE(A4,"➔ 결과:Nike_ShoesNike
이를 하나의 수식으로 합치면 다음과 같습니다.
=TEXTBEFORE(TEXTAFTER(A4, “_”, 2), “_”)
어떤가요? MID와 FIND를 중첩하는 것보다 훨씬 직관적이고 수정하기도 편합니다. 브랜드 위치가 바뀌면 숫자 2만 3으로 고쳐주면 되니까요.

보너스: 데이터가 없을 때 에러 방지하기 (If Not Found)
만약 TEXTBEFORE(A1, "_")를 썼는데 셀에 언더바(_)가 하나도 없다면? 엑셀은 가차 없이 #N/A 에러를 띄웁니다. 보기에 참 싫죠. 보통은 IFERROR 함수로 감싸지만, TEXTBEFORE/AFTER 함수는 자체적으로 에러 처리 기능을 가지고 있습니다.
=TEXTBEFORE(A1, "_", 1, 0, 0, "구분기호없음")
맨 마지막 인수에 “구분기호없음”이나 빈칸(“”)을 넣어주면, 에러 대신 우리가 지정한 텍스트가 깔끔하게 출력됩니다. 수식이 길어지는 것을 방지하는 세심한 배려가 돋보이는 기능입니다.
| 비교 항목 | 구식 방법 (LEFT/MID/FIND) | 신기술 (TEXTBEFORE/AFTER) |
|---|---|---|
| 난이도 | ★★★★★ (함수 중첩 지옥) | ★☆☆☆☆ (말하는 대로 써짐) |
| 유연성 | 글자 수 바뀌면 에러 발생 | 구분 기호 기준이라 자동 대응 |
| 방향성 | 무조건 왼쪽부터 계산 | 음수(-)로 뒤에서부터 계산 가능 |
| 가독성 | 암호 해독 수준 | 누구나 이해 가능 |
💡 더 깊이 알아보고 싶다면? (공식 가이드)
TEXTBEFORE와 TEXTAFTER 함수는 Microsoft 365 및 웹용 Excel(2022년 이후 업데이트)에서 사용할 수 있는 최신 함수입니다. 내 엑셀 버전에 따른 지원 여부가 궁금하시다면 마이크로소프트 공식 지원 문서(TEXTBEFORE)를 확인해 보세요.
마치며
지금까지 복잡하게 얽힌 텍스트 덩어리를 외과 수술 집도하듯 깔끔하게 분리해 주는 TEXTBEFORE / TEXTAFTER 함수에 대해 아주 상세하게 알아보았습니다.
이제 최 사원은 5,000개의 데이터 정제를 단 1분 만에 끝내고, 팀장님께 “보고서 완료했습니다”라고 메신저를 보낸 뒤 여유롭게 점심 메뉴를 고를 수 있게 되었습니다. 여러분도 오늘 당장, 회사 서버에서 내려받은 지저분한 로우 데이터(Raw Data) 파일을 열어서 이 함수를 적용해 보세요. “와, 내가 그동안 이걸 왜 손으로 하고 있었지?”라는 탄식과 함께 진정한 ‘칼퇴’의 기쁨을 맛보실 수 있을 겁니다. 다음 시간에는 드래그 없이 순번 1만 개를 1초 만에 채우는 SEQUENCE 함수의 마법으로 찾아오겠습니다. 지금까지 직장인 엑셀 꿀팁 저장소였습니다!