
엑셀의 혁명! REGEXEXTRACT 함수로 복잡한 패턴 데이터 1초 만에 추출하기
안녕하세요. 대한민국 직장인들의 피 같은 퇴근 시간을 지켜드리고 엑셀 실력을 데이터 엔지니어 수준으로 끌어올려 드리는 직장인 엑셀 꿀팁 저장소입니다! 오늘은 엑셀 역사상 가장 혁명적이고 파격적인 신기능이자, 데이터 정제의 끝판왕으로 불리는 REGEXEXTRACT 함수를 활용해 엉망으로 꼬인 비정형 데이터 속에서 원하는 패턴만 1초 만에 추출하는 완벽 가이드를 시작하겠습니다.
지난 시간에는 보고서의 가독성을 극대화하는 상하한선 포함 동적 목표 대비 실적 차트(Chart) 만들기를 통해 데이터 시각화의 정점을 경험해 보았습니다. 경영진의 마음을 사로잡는 완벽한 대시보드와 차트를 구축하는 방법을 배웠으니, 이제 다시 엑셀 실무의 가장 근본적이고 고통스러운 영역, 바로 ‘데이터 전처리(Data Preprocessing)’ 단계로 돌아와 보겠습니다.
영업지원팀 최 사원은 오늘 아침 마케팅 부서에서 넘겨받은 ‘이벤트 참여자 명단’ 파일을 열어보고 그대로 굳어버렸습니다. 무려 1만 줄이 넘는 데이터가 엑셀 시트에 빼곡하게 채워져 있었는데, 문제는 ‘비고’란에 입력된 텍스트의 상태가 그야말로 참혹했기 때문입니다. 어떤 고객은 [성함: 김철수, 연락처: 010-1234-5678, 이메일: kim@naver.com]이라고 정직하게 적어주었지만, 어떤 고객은 [010.9876.5432 / 이영희 / lee_99@gmail.com] 처럼 순서도 다르고 기호도 마음대로 입력해 두었습니다. 심지어 띄어쓰기조차 제각각이었습니다.
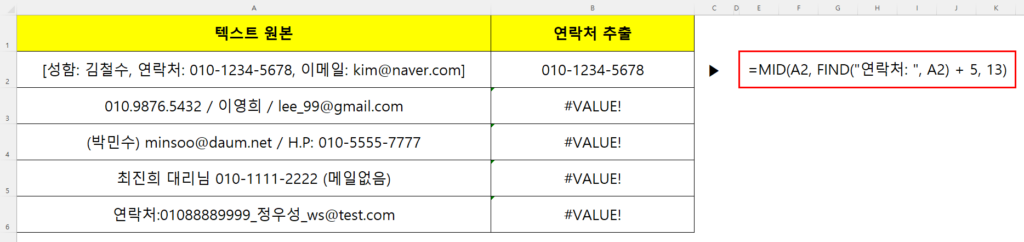
팀장님은 이 파일에서 “고객 휴대폰 번호와 이메일 주소만 따로 열을 만들어서 10분 안에 문자 발송 리스트로 정리해 와!”라는 불호령을 내립니다. 최 사원은 다급한 마음에 엑셀의 전통적인 텍스트 추출 함수인 FIND, LEFT, MID 함수를 총동원해 봅니다. 하지만 ‘010’의 위치가 셀마다 전부 다르고, 구분자가 하이픈(-)인지 마침표(.)인지조차 통일되지 않은 이 지옥의 데이터 앞에서는 #VALUE! 에러만 무한대로 쏟아질 뿐입니다. 결국 눈물을 머금고 수동으로 복사하고 붙여넣기를 반복하는 최 사원. 여러분도 이런 끔찍한 노가다를 경험해 보신 적이 있으신가요?
정규표현식(Regular Expression)이란 무엇이며 왜 혁명인가?
이런 절망적인 상황에서 우리를 구원해 줄 동아줄이 바로 오늘 소개할 REGEXEXTRACT 함수입니다. 이 함수를 이해하려면 먼저 그 근간이 되는 정규표현식(Regular Expression, 줄여서 Regex)이라는 개념을 알아야 합니다.
정규표현식이란 특정한 규칙이나 형식을 가진 문자열의 집합을 컴퓨터가 이해할 수 있도록 표현하는 ‘패턴 매칭(Pattern Matching) 언어’입니다. 원래 이 기술은 파이썬(Python), 자바(Java), 자바스크립트(JavaScript) 같은 전문 프로그래밍 언어에서 데이터 개발자들이 텍스트를 크롤링하거나 정제할 때만 사용하던 고급 기술이었습니다. 그런데 마이크로소프트가 이 막강한 프로그래머들의 무기를 엑셀 일반 사용자들도 수식 창에서 곧바로 쓸 수 있도록 전격 도입한 것입니다!
- 기존 엑셀 함수의 한계: “A라는 글자가 왼쪽에서 몇 번째에 있어?” 혹은 “공백을 기준으로 텍스트를 잘라줘”와 같이 ‘고정된 텍스트와 위치’에 의존합니다. 형식이 1mm만 틀어져도 즉각 에러를 뿜어냅니다.
- 정규표현식 함수의 위력: “숫자 3개, 기호 1개, 숫자 4개, 기호 1개, 숫자 4개로 뭉쳐진 덩어리를 찾아줘”와 같이 데이터의 ‘추상적인 패턴(Pattern)’ 그 자체를 인식합니다. 위치가 어디에 있든, 주변에 쓰레기 텍스트가 얼마나 많든 귀신같이 목표물만 추적해서 낚아챕니다.
이러한 패러다임의 변화는 실무에서 수백, 수천 배의 생산성 격차를 만들어냅니다. 데이터가 얼마나 더럽고 불규칙하든 상관없습니다. 그 안에 숨겨진 고유의 ‘규칙’만 정의해 주면 REGEXEXTRACT 함수가 모든 것을 해결해 줍니다.
REGEXEXTRACT 함수 기본 문법 완벽 해부
그렇다면 이 마법 같은 함수를 어떻게 사용하는지 문법 구조를 상세히 뜯어보겠습니다.
=REGEXEXTRACT(text, pattern, [return_mode], [case_sensitivity])
=REGEXEXTRACT(원본 텍스트, 정규표현식 패턴, [반환 모드], [대소문자 구분])
인수가 4개나 되지만 겁먹을 필요 없습니다. 실무에서 핵심적으로 다루는 것은 앞의 두 가지 필수 인수, 즉 어떤 셀(text)에서, 어떤 패턴(pattern)을 찾을 것인가입니다. 정규표현식을 엑셀에 명령하기 위해 알아두어야 할 가장 기초적이고 강력한 기호(메타 문자) 5가지를 먼저 암기해 봅시다.
| 정규식 기호 | 의미 (컴퓨터와의 약속) | 엑셀 실무 활용 예시 |
|---|---|---|
\d | 모든 숫자 (0부터 9까지) | 나이, 금액, 날짜, 전화번호 추출 시 필수 |
\w | 알파벳, 숫자, 밑줄(_) 문자 | 아이디, 상품 코드 등 영문+숫자 조합 추출 |
{n} | 앞의 문자가 정확히 n번 반복됨 | \d{4} = 숫자 4개가 연달아 나옴 |
+ | 앞의 문자가 1번 이상 계속 반복됨 | 글자 길이가 가변적일 때 하나로 묶어서 추출 |
[ ] | 괄호 안의 문자 중 하나와 일치 | [-.] = 하이픈(-)이나 마침표(.) 중 하나 |
실무 밀착 예제 1: 지옥의 텍스트에서 휴대폰 번호만 구출하기
자, 이제 최 사원이 마주한 첫 번째 미션인 ‘휴대폰 번호 추출’을 정규표현식으로 우아하게 해결해 보겠습니다. 한국의 휴대폰 번호는 일반적으로 010-1234-5678 형태를 띱니다. 하지만 앞서 보았듯 기호가 010.1234.5678 처럼 마침표로 되어 있을 수도 있습니다.
이 번호의 ‘패턴’을 정규식 기호로 번역해 봅시다.
1. 숫자 3개: \d{3}
2. 구분 기호(하이픈 또는 마침표): [-.]
3. 숫자 4개: \d{4}
4. 구분 기호(하이픈 또는 마침표)가 있을 수도 없을 수도 있음: [-.]?
5. 숫자 4개: \d{4}
이것을 그대로 이어 붙이면 우리가 찾고자 하는 완벽한 패턴이 완성됩니다! A2 셀에 지저분한 텍스트가 있다고 가정하고 수식을 작성해 보겠습니다.
=REGEXEXTRACT(A2, "\d{3}[-.]?\d{4}[-.]?\d{4}")
이 수식을 입력하고 엔터를 치는 순간, 기적이 일어납니다. A2 셀의 텍스트 길이가 10자든 100자든, 휴대폰 번호가 맨 앞에 있든 맨 뒤에 숨어 있든 상관없습니다. 엑셀은 문자열 전체를 스캔하다가 저 패턴과 정확히 일치하는 숫자 덩어리만 핀셋으로 쏙 뽑아서 결과값으로 반환해 줍니다. 1만 줄 자동 채우기 더블클릭 한 번이면 10분은커녕 단 1초 만에 최 사원의 첫 번째 미션이 끝납니다.
![REGEXEXTRACT 함수와 정규표현식 패턴(\d{3}[-.]\d{4}[-.]\d{4})을 사용하여 복잡한 텍스트 문장 속에서 휴대폰 번호만 깔끔하게 추출되어 나온 결과 화면](https://fix-library.com/wp-content/uploads/2026/02/excel-REGEXEXTRACT-formula3-1024x239.png)
실무 밀착 예제 2: 규칙이 없는 이메일 주소 발라내기
휴대폰 번호는 그나마 자릿수라도 정해져 있지만, 이메일 주소는 더욱 악랄합니다. 아이디 길이도 다르고, 도메인(naver.com, gmail.com 등)의 길이도 천차만별입니다. 전통적인 함수로는 골치가 아프지만, REGEXEXTRACT 함수에게는 식은 죽 먹기입니다.
이메일의 구조적 패턴은 “어떤 영문/숫자 뭉치 + @ + 어떤 영문/숫자 뭉치 + . + 영문 확장자”입니다. 이를 정규식으로 번역하면 다소 길어 보이지만 논리는 아주 명확합니다.
=REGEXEXTRACT(A2, "[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")
[a-zA-Z0-9._%+-]+: 소문자, 대문자, 숫자, 특정 기호들이 1개 이상(+) 연속되는 아이디 부분입니다.@: 반드시 골뱅이 기호가 중간에 들어가야 합니다.[a-zA-Z0-9.-]+: 이메일 제공 업체의 도메인 이름 부분입니다.\.[a-zA-Z]{2,}: 마지막에 진짜 마침표(\.)가 오고 그 뒤에 com, net 같은 확장자가 2글자 이상 온다는 뜻입니다.
이 마법의 주문 한 줄을 복사해서 붙여넣기만 하면, 텍스트 틈바구니에 교묘하게 숨어있는 이메일 주소만 완벽하게 분리되어 나옵니다. 데이터 정제 업무의 혁신이라는 말이 결코 과장이 아님을 실감하게 될 것입니다.
엑셀 고수의 비밀 무기: 캡처 그룹(Capture Group)으로 알맹이만 빼오기
여기서 만족하기엔 이릅니다. 정규표현식 기능의 진짜 꽃이자 하이라이트는 바로 소괄호 ( )를 활용하는 ‘캡처 그룹(Capture Group)’ 기술입니다. 이 기능은 전체 패턴의 문맥은 파악하되, 내가 실제로 결과로 반환받고 싶은 ‘핵심 알맹이’만 따로 지정할 때 사용합니다.
예를 들어 물류팀에서 [배송상태: 출고완료 / 송장번호: INV-2024-999] 라는 텍스트가 있다고 가정해 보겠습니다. 여기서 우리가 뽑고 싶은 것은 ‘INV-2024-999’라는 송장번호 데이터뿐입니다.
일반적인 함수 조합이라면 TEXTAFTER(A2, "송장번호: ")를 쓰고 그 뒤에 남은 대괄호 ]를 지우기 위해 다시 한번 함수를 씌워야 합니다. 하지만 REGEXEXTRACT와 캡처 그룹을 쓰면 단 한 번에 끝납니다.
=REGEXEXTRACT(A2, "송장번호: (.*)\]",2)
수식의 해석은 이렇습니다. “엑셀아, ‘송장번호: ‘로 시작하고 대괄호 ‘]’로 끝나는 부분을 찾아줘. 그런데 마지막에 숫자 2를 적었으니 소괄호 ( )로 묶인 부분, 즉 그 사이에 있는 내용물(.*)만 화면에 출력해 줘! 라는 뜻입니다. 불필요한 레이블 텍스트는 버리고 원하는 데이터만 우아하게 추출하는 이 기술을 마스터하면 엑셀에서 정제하지 못할 데이터는 존재하지 않습니다.
![REGEXEXTRACT 함수의 캡처 그룹(소괄호) 기능을 활용하여, 텍스트 중 '송장번호: '와 ']' 사이에 있는 핵심 데이터 알맹이만 정확히 추출해 내는 고급 정규표현식 수식 화면](https://fix-library.com/wp-content/uploads/2026/02/excel-REGEXEXTRACT-formula4-1024x201.png)
사용 전 필수 확인 사항 (버전 호환성)
이토록 강력한 REGEXEXTRACT 함수이지만 한 가지 주의할 점이 있습니다. 바로 버전에 따른 호환성입니다. 이 함수는 마이크로소프트가 도입한 아주 따끈따끈한 최신 기능입니다.
현재 Microsoft 365 구독자 중에서도 최신 업데이트 채널을 사용 중인 사용자에게 순차적으로 배포되고 있습니다. 만약 내 엑셀에서 =REGEX...를 타이핑했는데 자동 완성 목록에 함수가 뜨지 않는다면 아직 해당 PC의 엑셀 버전에 기능이 활성화되지 않은 것입니다.
이럴 때는 당황하지 마시고 인터넷 브라우저를 열어 ‘웹용 엑셀(Excel for the Web)’에 접속해 보세요. 마이크로소프트는 웹 버전에 신기능을 가장 먼저 반영하기 때문에, 계정만 있다면 누구나 웹상에서 즉시 이 막강한 정규표현식 함수들을 테스트하고 업무에 적용해 볼 수 있습니다.
💡 정규표현식의 세계로 더 깊이 들어가고 싶으신가요? (공식 가이드)
정규표현식(Regex)은 엑셀을 넘어 파이썬, R 데이터 분석, 구글 스프레드시트 등 전산 세계 전체를 관통하는 필수 글로벌 표준 문법입니다. 엑셀에 새롭게 추가된 정규표현식 함수 3형제(REGEXEXTRACT, REGEXREPLACE, REGEXTEST)에 대한 정확한 기술 사양과 마이크로소프트가 제공하는 더 다양한 패턴 예제가 궁금하시다면 마이크로소프트 공식 REGEXEXTRACT 지원 문서를 반드시 참고해 보시기를 강력히 권장합니다.
마치며
지금까지 엑셀 데이터 정제의 패러다임을 완전히 뒤집어버린 혁명적인 신기능, REGEXEXTRACT 함수를 활용하여 복잡하고 불규칙한 패턴 데이터를 1초 만에 추출해 내는 완벽한 방법을 알아보았습니다.
솔직히 말씀드리면, 처음 \d나 [a-zA-Z] 같은 정규표현식 기호들을 마주하면 마치 암호문이나 외계어처럼 느껴져 거부감이 드는 것이 당연합니다. 하지만 이 규칙은 한 번만 제대로 눈에 익혀두면 평생 써먹을 수 있는 강력한 무기가 됩니다. 수천 줄의 엉망진창 데이터를 보며 수동으로 마우스 드래그를 하느라 1시간씩 야근을 하던 과거의 비효율에서 영원히 탈출할 수 있는 치트키가 바로 이 함수이기 때문입니다. 남들이 텍스트 나누기와 FIND 함수로 머리를 쥐어뜯고 있을 때, 여러분은 단 한 줄의 세련된 패턴 수식으로 업무를 끝내고 커피 한 잔의 여유를 즐기실 수 있습니다.
오늘 당장 회사 컴퓨터에 저장된 가장 지저분하고 복잡한 텍스트 데이터 파일을 하나 열어보세요. 그리고 오늘 배운 휴대폰 번호 추출 패턴이나 이메일 추출 패턴을 직접 수식 창에 타이핑해 보시기 바랍니다. 모니터 위로 쏟아져 나오는 깔끔한 데이터들을 보는 순간, 여러분의 엑셀 실력은 이미 일반 직장인을 넘어 데이터 엔지니어의 영역에 발을 들여놓게 된 것입니다.
자, 지저분한 데이터를 완벽하게 정제하고 예쁜 차트로 시각화하는 방법까지 모두 마스터했습니다. 그렇다면 이렇게 깔끔해진 수만 줄의 데이터베이스 속에서 **내가 원하는 특정 조건(예: 영업1팀이면서 매출이 100만 원 이상인 사람)에 맞는 데이터만 실시간으로 필터링해서 화면에 띄워주는 자동 대시보드**는 어떻게 만들까요? 과거에는 고급 필터나 피벗 테이블로 번거롭게 작업해야 했지만, 이제는 함수 하나면 충분합니다.
지금까지 여러분의 칼퇴를 책임지는 직장인 엑셀 꿀팁 저장소였습니다. 감사합니다!